ElasticSearch left-join 플러그인 IntelliJ 구동 및 소스 분석
2020, Oct 15
실습 환경
- Host OS : Window 10
- git
- IDE : intelliJ
- Java : 11 version
git clone
git clone https://github.com/danawalab/left-join-plugin
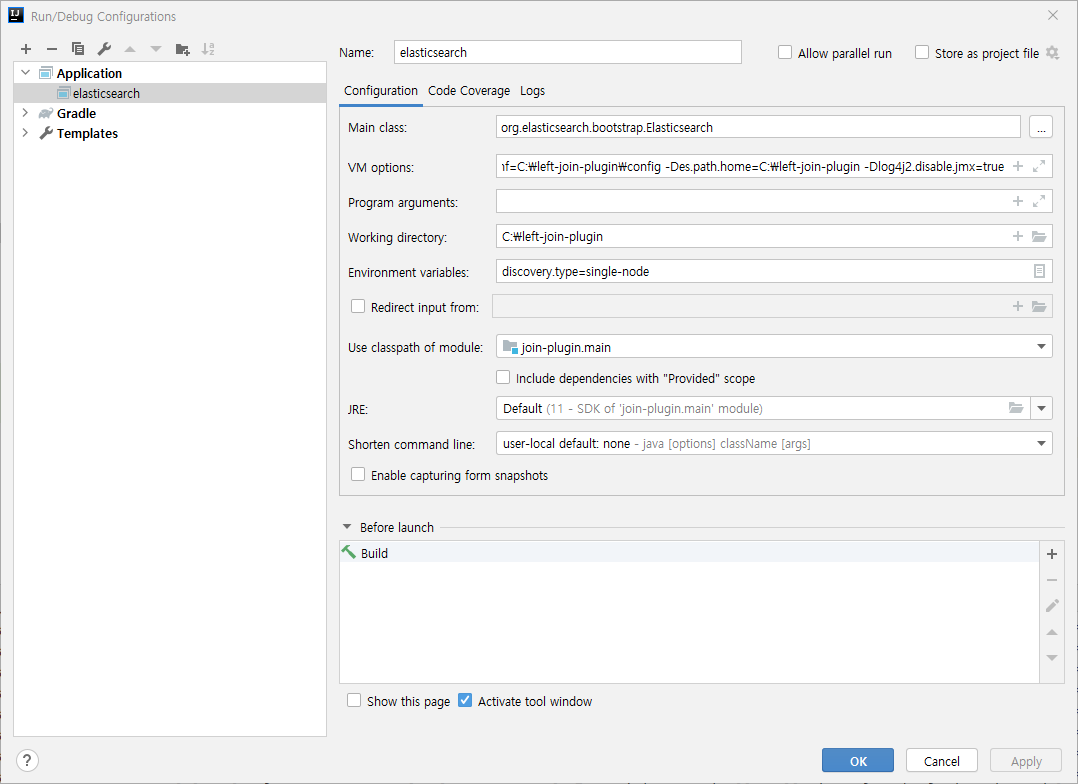
Main class, VM option, 환경 변수 세팅
- README.md 에도 잘 나와있지만 어떻게 설정하는지 어렵다면 필자의 예제 세팅을 참고하도록 한다. 오류 없이 정상적으로 실행된다면 잘 세팅한 것이다.
Main class : org.elasticsearch.bootstrap.Elasticsearch
VM options : -Xmx4g -Xms4g -Des.path.conf=C:\left-join-plugin\config -Des.path.home=C:\left-join-plugin -Dlog4j2.disable.jmx=true
Environment variables : discovery.type=single-node
소스 분석
- LeftJoinPlugin : 액션 핸들러를 등록
- LeftJoinAction : 핵심 로직
- JSONUtils : 데이터 가공 Util
- EsUtils : 쿼리 조회 Util
- Join : 연관 키워드 관련 VO
package com.danawa.search;
import org.apache.logging.log4j.Logger;
import org.apache.lucene.search.TotalHits;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.node.NodeClient;
import org.elasticsearch.common.inject.Inject;
import org.elasticsearch.common.logging.Loggers;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.xcontent.*;
import org.elasticsearch.rest.BaseRestHandler;
import org.elasticsearch.rest.BytesRestResponse;
import org.elasticsearch.rest.RestController;
import org.elasticsearch.rest.RestRequest;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.json.JSONArray;
import org.json.JSONObject;
import java.io.IOException;
import java.util.*;
import static org.elasticsearch.rest.RestStatus.OK;
public class LeftJoinAction extends BaseRestHandler {
private static Logger logger = Loggers.getLogger(LeftJoinAction.class, "");
private static final String JOIN_FIELD = "join";
@Inject
public LeftJoinAction(Settings settings, RestController controller) {
controller.registerHandler(RestRequest.Method.GET, "/{index}/_left", this);
controller.registerHandler(RestRequest.Method.POST, "/{index}/_left", this);
}
@Override
public String getName() {
return "rest_handler_left_join_plugin";
}
@Override
protected RestChannelConsumer prepareRequest(RestRequest request, NodeClient client) throws IOException {
try {
JSONObject content = JSONUtils.parseRequestBody(request);
String parentIndices = request.param("index");
// 1. 조인 필드 추출
//JSON 배열을 선언
JSONArray joinArr = new JSONArray();
//JSONObject(JOIN_FIELD) 값이 존재하면
if (content.has(JOIN_FIELD)) {
try {
//joinArr이라는 JSON 배열에 넣는다.
joinArr = content.getJSONArray(JOIN_FIELD);
} catch (Exception e) {
//예외가 발생할 경우 JsonObject를 가져와서 JoinArr 배열에 넣어준다.
JSONObject joinJsonObject = content.getJSONObject(JOIN_FIELD);
joinArr.put(joinJsonObject);
}
//배열에 넣어주는 작업이 끝날 경우 JSONObject는 제거한다.
content.remove(JOIN_FIELD);
}
//joinArr 배열에 길이가 0이면 IOException을 뱉어준다.
if (joinArr.length() == 0) {
throw new IOException("join Arrays Empty");
}
// 2. 메인 쿼리 조회
SearchResponse parentResponse = EsUtils.search(request, client, parentIndices, content.toString());
//메인 쿼리 Hits 변수 선언 및 초기화
SearchHits parentSearchHits = parentResponse.getHits();
// 3. 메인 쿼리 연관 키워드 조인 검색
// 연관 키워드 조인 리스트 선언
List<Join> joins = new ArrayList<>();
// JSONArray를 Object 리스트로 변환한다.
List<Object> objectJoinList = joinArr.toList();
// Object 리스트의 사이즈를 선언 및 초기화 한다.
int objectJoinListSize = objectJoinList.size();
//Object 리스트의 사이즈 만큼 반복을 하면서 연관 키워드 조인 리스트에 해당 값들을 넣는다.
for (int i = 0; i < objectJoinListSize; i++) {
Join join = new Join((Map<String, Object>)objectJoinList.get(i));
//index 필드가 없을 경우 IOExetion 발생
if (join.getIndex() == null) {
throw new IOException("[Index] field is required.");
//parent 필드가 없을 경우 IOExetion 발생
} else if (join.getParent() == null) {
throw new IOException("[parent] field is required.");
//child 필드가 없을 경우 IOExetion 발생
} else if (join.getChild() == null) {
throw new IOException("[child] field is required.");
}
//메인 쿼리 Hits와 parent 인덱스의 정보로 HashSet 값을 가져옴
Set<String> relationalValues = extractValues(parentSearchHits, join.getParent());
//메인 키워드 연관 키워드 검색
List<SearchHit> childSearchHits = EsUtils.childSearch(client, join, relationalValues);
//연관 키워드 hits를 Join 객체에 넣음
join.setSearchHits(childSearchHits);
joins.add(join);
}
// 4. parent innerHit 에 child hit 추가
//= parentResponse.getHits().getHits();
SearchHit[] parentSearchHitArr = parentSearchHits.getHits();
//해당 반복문을 돌면서 메인 쿼리 Hits의 하위 Hits를 가공해서 메인 쿼리 parentSearchHit 배열에 넣는다.
for (int i = 0; i < parentSearchHitArr.length; i++) {
SearchHit searchHit = parentSearchHitArr[i];
//searchHit JSON Data를 StringMap으로 가공
Map<String, String> parentFlatMap = JSONUtils.flattenToStringMap(searchHit.getSourceAsMap());
//maxScore 변수를 float로 선언 및 초기화
float maxScore = 0.0f;
//임시 ChildSearchHits 리스트를 선언
List<SearchHit> tmpChildSearchHits = new ArrayList<>();
int joinsSize = joins.size();
//연관 키워드 갯수에 맞게 반복문
for (int j = 0; j < joinsSize; j++) {
Join join = joins.get(j);
//parent 값 가져오기
String parent = parentFlatMap.get(join.getParent());
//parent가 null이 아닌 경우에만 동작
if (parent != null) {
//연관 키워드 Hits 리스트 변수 선언 및 초기화
List<SearchHit> childSearchHits = join.getSearchHits();
//연관 키워드 갯수 변수 선언 및 초기화
int childSearchHitsSize = childSearchHits.size();
//연관 키워드 갯수 만큼 반복문 수행
for (int k = 0; k < childSearchHitsSize; k++) {
SearchHit childSearchHit = childSearchHits.get(k);
//childSearchHit JSON Data를 StringMap으로 가공
Map<String, String> childFlatMap = JSONUtils.flattenToStringMap(childSearchHit.getSourceAsMap());
//child 값 가져오기
String child = childFlatMap.get(join.getChild());
//parent와 child가 같으면
if (parent.equals(child)) {
//임시 ChildSearchHits에 연관키워드 리스트를 모두 넣는다.
tmpChildSearchHits.addAll(childSearchHits);
//maxScore값 보다 연관키워드의 maxScore 값보다 크면 maxScore값을 연관키워드의 maxScore 값으로 세팅
if (maxScore < join.getMaxScore()) {
maxScore = join.getMaxScore();
}
break;
}
}
}
}
// append child
Map<String, SearchHits> child = new HashMap<>();
//child HashMap에 _child라는 키값으로 SearchHits 객체를 넣어준다.
child.put("_child",
new SearchHits(tmpChildSearchHits.toArray(new SearchHit[0]),
new TotalHits(tmpChildSearchHits.size(), TotalHits.Relation.EQUAL_TO),
maxScore));
//parentSearchHitArr 배열 안의 innerHits 값에 child 값을 세팅해준다.
parentSearchHitArr[i].setInnerHits(child);
}
//return 값 세팅
return channel -> {
XContentBuilder xContentBuilder = channel.newBuilder(XContentType.JSON, true);
parentResponse.toXContent(xContentBuilder, new ToXContent.MapParams(request.params()));
BytesRestResponse bytesRestResponse = new BytesRestResponse(OK, xContentBuilder);
channel.sendResponse(bytesRestResponse);
};
} catch (Throwable e) {
logger.error("[LEFT JOIN PLUGIN ERROR]", e);
throw new IOException("[LEFT JOIN PLUGIN ERROR] " + e.getMessage(), e);
}
}
//메인 쿼리의 searchHits와 field값을 통해 HashSet을 추출함
Set<String> extractValues(SearchHits searchHits, String field) {
//TotalHits 값이 0이면 빈 HashSet을 리턴함.
if (searchHits.getTotalHits().value == 0) {
return new HashSet<>();
}
//extractValues HashSet 선언
Set<String> extractValues = new HashSet<>();
//메인 쿼리 Hits 컬렉션에 저장되어있는 요소를 읽어옴
Iterator<SearchHit> iterator = searchHits.iterator();
//컬렉션 요소가 끝날때까지 반복문을 돌면서 extractValues HashSet에 저장
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next();
Map<String, String> flatSourceMap = JSONUtils.flattenToStringMap(searchHit.getSourceAsMap());
String val = flatSourceMap.get(field);
if (val != null) {
extractValues.add(val);
}
}
return extractValues;
}
}