ElasticSearch Kibana Visualize 파헤치기
2020, Oct 08
시각화 (Visualize)
- Visualize를 사용하면 Elasticsearch 인덱스에서 데이터 시각화를 생성 한 다음 분석을 위해 대시 보드에 추가 할 수 있음 (고로 Visualize를 사용하지 않으면 대시 보드에 추가할 수 없음)
- Elastic Search 집계를 사용하여 데이터를 추출하고 처리하여 차트를 만들 수 있음
시각화 유형
Lens
- 표시하려는 데이터 필드를 끌어서 놓기만 하면 기본 시각화를 작성할 수 있음
자주 사용되는 시각화
- Line, area, and bar charts(선, 영역 및 막대 차트) : X / Y 차트에서 서로 다른 계열을 비교
- Pie chart(파이 차트) : 합계에 대한 각 소스 기여도를 표시
- Data table(데이터 테이블) : 집계를 테이블 형식으로 병합
- Metric(메트릭) : 단일 숫자를 표시
- Goal and gauge(목표 및 게이지) : 진행률 표시기와 함께 숫자를 표시
- Tag cloud(태그 클라우드) : 중요도가 높은 단어를 표시
시각화 구성 실습 (막대 차트)
- 클릭한 로그 데이터에 따른 키워드 순위를 막대차트로 표현
- X축은 키워드 갯수 (일반적으로 X축은 날짜 히스토그램을 사용한다고 함)
update버튼을 눌러야 적용됨
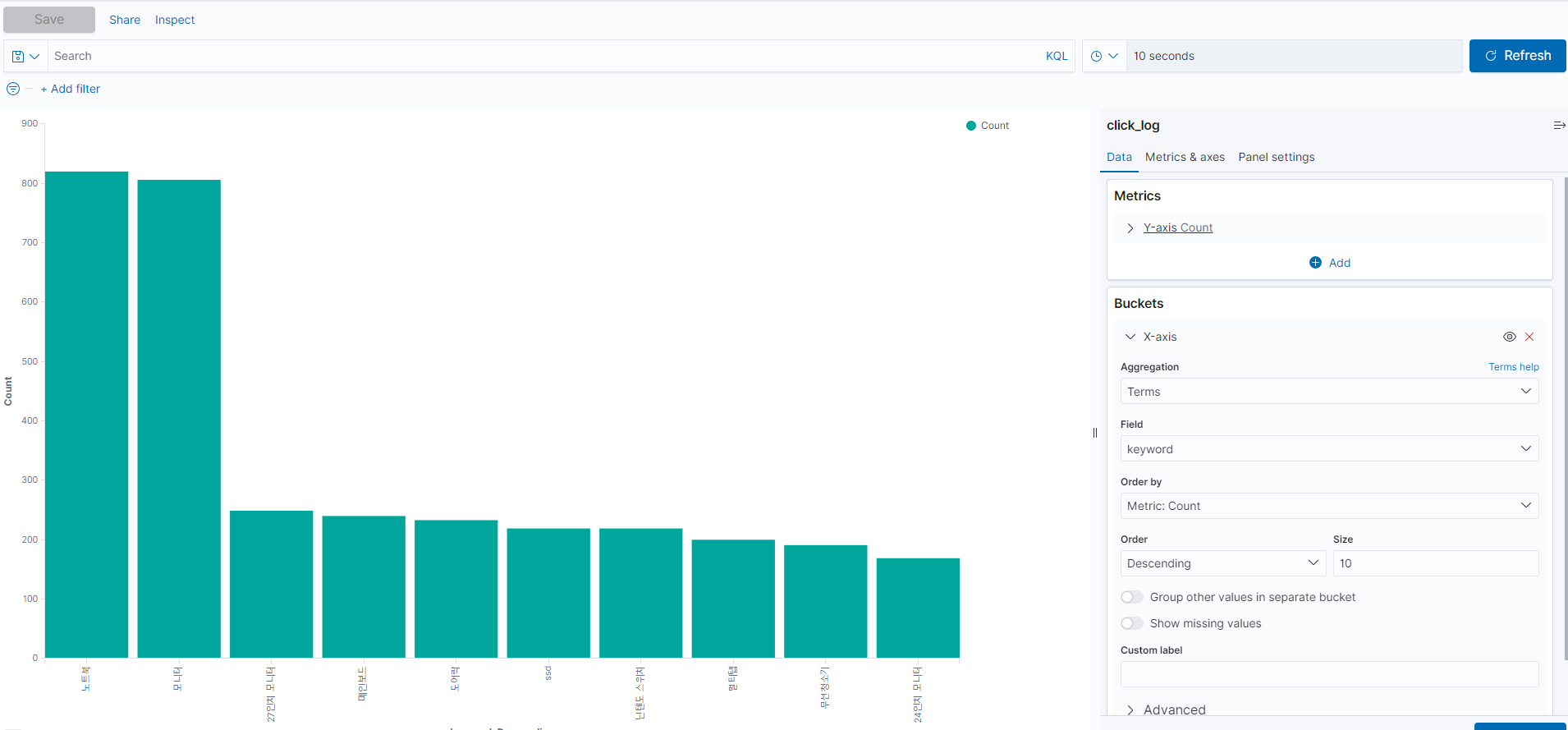
- 아래의
=버튼으로 드래그를 하면 집계 순서를 변경할 수 있음
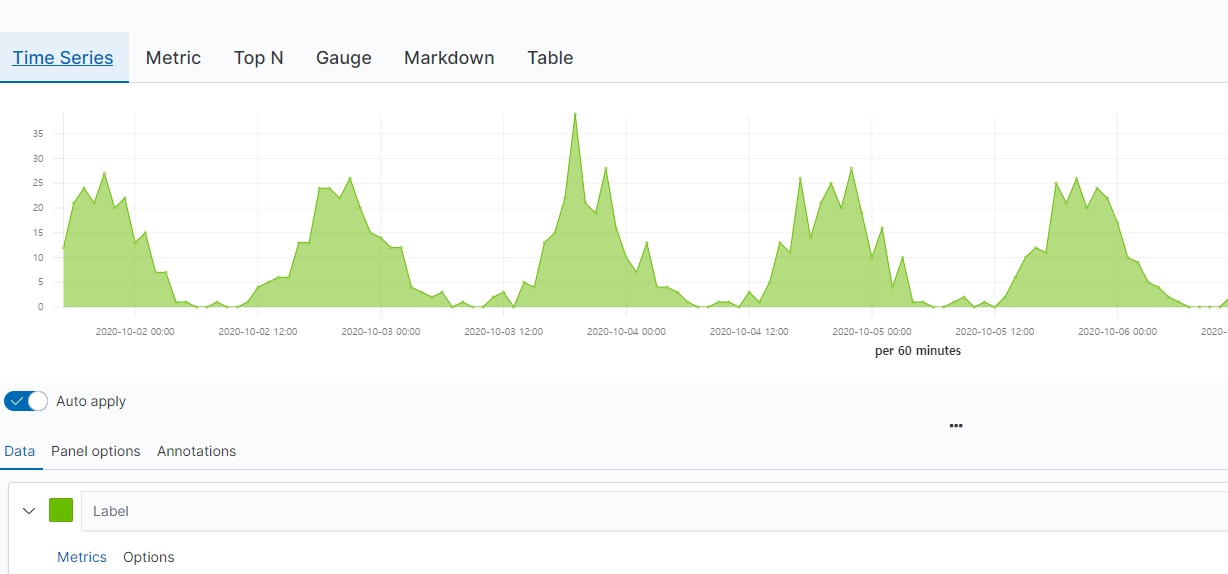
TSVB
- 파이프 라인 집계를 사용하여 시계열 데이터를 시각화
- Kibana에서 제공하는 샘플 데이터로 실습
- TSVB의 메뉴
- Time Series : 여러 Y축과 함께 영역, 선, 막대 및 단계를 지원하는 히스토그램 시각화
- Metic : 데이터의 최신 숫자를 표시
- Top N : Y축이 인련의 메트릭을 기반으로 하고 X축이 계열의 최신 값인 가로 막대 차트
- Gauge : 최신 값을 기반으로 한 단일 값 게이지 시각화
- Markdown : 마크다운 텍스트 및 Mustacle 템플릿 구문을 사용하여 데이터를 편집
- Table : 행에 표시할 필드 그룹과 표시할 데이터 열을 정의하여 여러 시계열의 데이터를 표시
Timelion
- 여러 시계열 데이터 세트의 데이터를 계산하고 결합
Maps
- Kibana에서 지리 공간 데이터를 표시
- Heat map : 행렬 내에 음영 처리된 셀을 표시
Dashboard tools
- Markdown widget : 자유 형식 정보 또는 지침 표시
- Controls : 대시 보드에 대화형 입력을 추가
Vega
- 쿼리 및 표시에 대한 제어
데이터 선택
- 시각화 할 데이터가 포함된 인덱스의 인덱스 패턴을 선택
- 저장된 검색에서 시각화를 작성하려면 사용하려는 저장된 검색의 이름을 클릭
- 롤업된 데이터를 사용하여 시각화를 작성하려면 데이터를 포함하는 인덱스 패턴을 선택
시각화 검사
- Kibana 툴바에서 Inspect를 클릭
- 데이터를 다운로드하려면 CSV 다운로드를 클릭
- Formatted CSV
- Raw CSV
- 데이터 수집 요청을 보려면 보기 드롭 다운에서 요청을 선택
시각화 저장
- 대시 보드 에서 시각화를 사용하려면 저장해야함.
- Kibana 도구 모음에서 저장을 클릭
- 시각화 제목 및 설명을 입력한 다음 시각화를 저장
시각화 공유
- 시각화를 완료하면 Kibana 외부에서 공유 가능
- 웹 페이지에 코드를 삽입(엑세스 권한이 있어야 함)
- Kibana 시각화에 대한 직접 링크를 공유
- PDF 보고서를 생성
- PNG 보고서를 생성
지원되는 집계
메트릭 집계(Metric aggregations)
- Average : 평균
- Count : 갯수 (버킷의 문서수를 시각화 할 수 있는 쿼리와 일치하는 총 문서수)
- Max : 최대값
- Median : 중앙값
- Min : 최소값
- Percentile rank : 백분위 순위
- Percentiles : 백분위 수
- Standard Deviation : 표준 편차
- Sum : 합계
- Top hit : 개별 문서의 샘플을 반환, 둘이상의 문서와 일치하는 경우 평균, 최소값, 최대값, 합계와 같은 결합하는 집계를 선택하여야 함.
- Unique Count : 버킷 내 필드의 카디널리티
부모 파이프 라인 집계(Parent pipeline aggregations)
시계열 데이터에 유용
부모 파이프 라인 집계에 대해 버킷 집계 및 지표 집계를 정의해야 함
- Bucket script : 부모 다중 버킷 집계에서 지표를 지정하는 각 버킷에 대해 계산을 수행하는 스크립트를 실행
- Cumulative sum : 누적 합계 계산
- Derivative : 평균이동, 특정 메트릭의 도함수를 계산
- Serial diff : 직렬 차이, 시계열 값이 다른 시차 또는 기간을 뺌
형제 파이프 라인 집계(Sibling pipeline aggregations)
많은 버킷을 하나로 압축
각 형제 파이프 라인 집계에 대해 버킷 집계 및 메트릭 집계를 정의해야함
- Average bucket : 평균 또는 평균 값 계산
- Max bucket : 최대값 계산
- Min bucket : 최소값 계산
- Sum bucket : 합계 계산
버킷 집계(Bucket aggregations)
문서의 내용에 따라 문서를 버킷으로 정렬
- Date histogram : 날짜 필드를 간격별로 버킷으로 분할
- Date range : 지정한 날짜 범위 내에 있는 값을 보고
- Filter : 각 필터로 문서 버킷을 만듦
- Geohash : Geohash 기반으로 포인트를 표시
- Geotile : 웹 맵 타일링을 기반으로 포인트를 그룹화
- Histogram : 숫자 필드에서 빌드
- IPv4 range : IPv4 주소 범위를 지정
- Range : 숫자 필드 값의 범위를 지정
- Significant terms : 집합에서 흥미롭거나 비정상적인 용어를 반환
- Terms : 표시할 특정 필드의 상위 또는 하위 n개 요소를 개수 또는 다른 지정항목별로 정렬